VSchema
Overview #
VSchema stands for Vitess Schema. It is an abstraction layer that presents a unified view of the underlying keyspaces and shards, and gives the semblance of a single MySQL server.
For example, VSchema will contain the information about the sharding key for a sharded table. When the application issues a query with a WHERE clause that references the key, the VSchema information will be used to route the query to the appropriate shard.
Architecture #
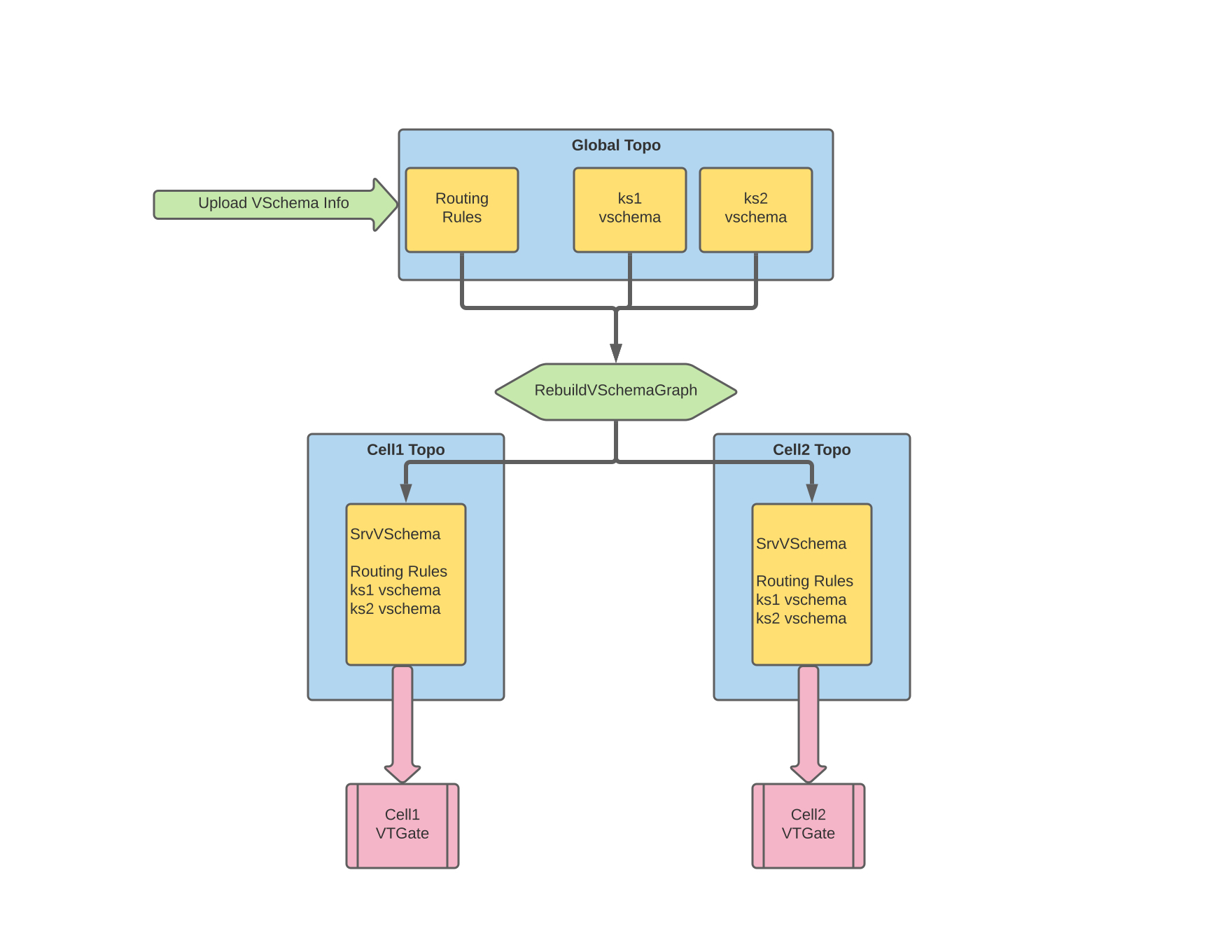
The VSchema is specified on a per-keyspace basis. Additionally, a separate set of RoutingRules can be specified. This information is stored in the global topology. A vtctld RebuildVSchemaGraph command combines the RoutingRules and the per-keyspace VSchemas into a unified data structure called SrvVSchema, which is deployed into the topo of each cell. The VTGates consume this information, which they use for planning and routing queries from the application.
Database Access Model #
A Vitess Keyspace is the logical equivalent to a MySQL database. The usual syntax used to access databases in mysql work in Vitess as well. For example, you can connect to a specific database by specifying the database name in the connection parameter. You can also change the database you are connected to through the use statement. While connected to a database, you can access a table from a different keyspace by qualifying the table name in your query, like select * from other_keyspace.table.
Tablet Types #
Unlike MySQL, the vitess servers unify all types of mysql servers. You can ask vitess to target a specific tablet type by qualifying it as part of the database name. For example, to access replica tablets, you may specify the database name as keyspace@replica. This name can also be specified in the connection string. If no tablet type is specified in the database name, then the value specified in VTGate's --default-tablet-type flag is used.
Unspecified Mode #
Additionally, you can connect without specifying a database name and still access tables without qualifying them by their keyspace. If the table name is unique across all keyspaces, then VTGate automatically sends the query to the associated keyspace. Otherwise, it returns an error. This mode is useful if you start off with a single keyspace and plan on splitting it into multiple parts.
You can still specify a tablet type for the unspecified mode. For example, you can connect to @replica if you want to access the replica tablets in unspecified mode.
Some frameworks require you to specify an explicit database name while connecting. In order to make them work in unspecified mode, you can specify the database name as @replica or @primary instead of a blank one.
Sharded keyspaces require a VSchema #
A VSchema is needed to tie together all the databases that Vitess manages. For a very trivial setup where there is only one unsharded keyspace, there is no need to specify a VSchema because Vitess will know that there is no other place to route a query.
If you have multiple unsharded keyspaces, you can still avoid defining a VSchema in one of two ways:
- Connect to a keyspace and all queries are sent to it.
- Connect to Vitess without specifying a keyspace (unspecified mode), but use qualified names for tables, like
keyspace.tablein your queries.
However, once the setup exceeds the above complexity, VSchemas become a necessity. Vitess has a working demo of VSchemas.
Sharding Model #
In Vitess, a keyspace is sharded by keyspace ID ranges. Each row is assigned a keyspace ID, which acts like a street address, and it determines the shard where the row lives. In some respect, one could say that the keyspace ID is the equivalent of a NoSQL sharding key. However, there are some differences:
- The
keyspace IDis a concept that is internal to Vitess. The application does not need to know anything about it. - There is no physical column that stores the actual
keyspace ID. This value is computed as needed.
This difference is significant enough that we do not refer to the keyspace ID as the sharding key. A Primary Vindex more closely resembles the NoSQL sharding key.
Mapping to a keyspace ID, and then to a shard, gives us the flexibility to reshard the data with minimal disruption because the keyspace ID of each row remains unchanged through the process.
Vindexes #
The Vschema contains the Vindex for any sharded tables. The Vindex tells Vitess where to find the shard that contains a particular row for a sharded table. Every VSchema must have at least one Vindex, called the Primary Vindex, defined. The Primary Vindex is unique: given an input value, it produces a single keyspace ID, or value in the keyspace used to shard the table. The Primary Vindex is typically a functional Vindex: Vitess computes the keyspace ID as needed from a column in the sharded table.
Sequences #
Auto-increment columns do not work very well for sharded tables. Vitess sequences solve this problem. Sequence tables must be specified in the VSchema, and then tied to table columns. At the time of insert, if no value is specified for such a column, VTGate will generate a number for it using the sequence table.
Reference tables #
Vitess allows you to create an unsharded table and deploy it into all shards of a sharded keyspace. The data in such a table is assumed to be identical for all shards. In this case, you can specify that the table is of type reference, and should not specify any vindex for it. Any joins of this table with an unsharded table will be treated as a local join.
Typically, such a table has a canonical source in an unsharded keyspace, and the copies in the sharded keyspace are kept up-to-date through VReplication.
Controlling cross-keyspace JOINs #
By default, Vitess will execute JOINs across tables in different keyspaces. You can restrict this behavior at two levels:
Globally via VTGate: Use the
--no-cross-keyspace-joinsflag when starting VTGate to deny all cross-keyspace JOINs.Per-keyspace via VSchema: Set
no_cross_keyspace_joins: truein a keyspace's VSchema to deny cross-keyspace JOINs involving that keyspace.
When cross-keyspace JOINs are denied, the planner rejects queries that join tables from different keyspaces with an error like:
cross-keyspace join between keyspaces 'ks1' and 'ks2' (use /*vt+ ALLOW_CROSS_KEYSPACE_JOINS */ to override)
The VTGate flag takes precedence—when --no-cross-keyspace-joins is set, cross-keyspace JOINs are denied globally regardless of per-keyspace VSchema settings.
Per-query override #
To override the restriction for a specific query, use the ALLOW_CROSS_KEYSPACE_JOINS comment directive:
SELECT /*vt+ ALLOW_CROSS_KEYSPACE_JOINS */ * FROM ks1.t1 JOIN ks2.t2 ON t1.id = t2.id;
Per-Keyspace VSchema #
The VSchema uses a flexible proto JSON format. Essentially, you can use snake_case or camelCase for the keys.
The configuration of your VSchema reflects the desired sharding configuration for your database, including whether or not your tables are sharded and whether you want to implement a secondary Vindex.
Commands #
You can use the following commands for maintaining the VSchema:
GetVSchema <keyspace>ApplyVSchema -- {--vschema=<vschema> || --vschema-file=<vschema file> || --sql=<sql> || --sql-file=<sql file>} [--cells=c1,c2,...] [--skip-rebuild] [--dry-run] [--strict] <keyspace>RebuildVSchemaGraph [--cells=c1,c2,...]GetSrvVSchema <cell>DeleteSrvVSchema <cell>
In order to verify that a VTGate has loaded SrvVSchema correctly, you can visit the /debug/vschema URL on the VTGate's http port.
Unsharded Table #
The following snippets show the necessary configs for creating a table in an unsharded keyspace:
Schema:
# lookup keyspace
create table name_user_idx(name varchar(128), user_id bigint, primary key(name, user_id));
VSchema:
// lookup keyspace
{
"sharded": false,
"tables": {
"name_user_idx": {}
}
}
For a normal unsharded table, the VSchema only needs to know the table name. No additional metadata is needed.
Sharded Table With Simple Primary Vindex #
To create a sharded table with a simple Primary Vindex, the VSchema requires more information:
Schema:
# user keyspace
create table user(user_id bigint, name varchar(128), primary key(user_id));
VSchema:
// user keyspace
{
"sharded": true,
"vindexes": {
"xxhash": {
"type": "xxhash"
}
},
"tables": {
"user": {
"column_vindexes": [
{
"column": "user_id",
"name": "xxhash"
}
]
}
}
}
Because Vindexes can be shared, the JSON requires them to be specified in a separate vindexes section, and then referenced by name from the tables section. The VSchema above simply states that user_id uses xxhash as Primary Vindex. The first Vindex of every table must be the Primary Vindex.
Specifying A Sequence #
Since user is a sharded table, it will be beneficial to tie it to a Sequence. However, the sequence must be defined in the lookup (unsharded) keyspace. It is then referred from the user (sharded) keyspace. In this example, we are designating the user_id (Primary Vindex) column as the auto-increment.
Schema:
# lookup keyspace
create table user_seq(id int, next_id bigint, cache bigint, primary key(id)) comment 'vitess_sequence';
insert into user_seq(id, next_id, cache) values(0, 1, 3);
For the sequence table, id is always 0. next_id starts off as 1, and the cache is usually a medium-sized number like 1000. In our example, we are using a small number to demonstrate how it works.
VSchema:
// lookup keyspace
{
"sharded": false,
"tables": {
"user_seq": {
"type": "sequence"
}
}
}
// user keyspace
{
"sharded": true,
"vindexes": {
"xxhash": {
"type": "xxhash"
}
},
"tables": {
"user": {
"column_vindexes": [
{
"column": "user_id",
"name": "xxhash"
}
],
"auto_increment": {
"column": "user_id",
"sequence": "lookup.user_seq"
}
}
}
}
If necessary, the reference to the sequence table lookup.user_seq can be escaped using backticks.
Specifying A Secondary Vindex #
The following snippet shows how to configure a Secondary Vindex that is backed by a lookup table. In this case, the lookup table is configured to be in the unsharded lookup keyspace:
Schema:
# lookup keyspace
create table name_user_idx(name varchar(128), user_id bigint, primary key(name, user_id));
VSchema:
// lookup keyspace
{
"sharded": false,
"tables": {
"name_user_idx": {}
}
}
// user keyspace
{
"sharded": true,
"vindexes": {
"name_user_idx": {
"type": "lookup",
"params": {
"table": "name_user_idx",
"from": "name",
"to": "user_id"
},
"owner": "user"
}
},
"tables": {
"user": {
"column_vindexes": [
{
"column": "name",
"name": "name_user_idx"
}
]
}
}
}
To recap, a checklist for creating the shared Secondary Vindex is:
- Create physical
name_user_idxtable in lookup database. - Define a routing for it in the lookup VSchema.
- Define a Vindex as type
lookupthat points to it. Ensure that theparamsmatch the table name and columns. - Define the owner for the Vindex as the
usertable. - Specify that
nameuses the Vindex.
Currently, these steps have to be currently performed manually. However, extended DDLs backed by improved automation will simplify these tasks in the future.
The columns field #
For a table, you can specify an additional columns field. This can be used for two purposes:
- Specifying that a column contains text. If so, the VTGate planner can rewrite queries to leverage mysql’s collation where possible.
- If the full list of columns is specified, then VTGate can resolve columns to their tables where needed, and also authoritative expand column lists, like in the case of a
select *orinsertstatements with no column list.
Here is an example:
"tables": {
"user": {
"column_vindexes": [
{
"column": "name",
"name": "name_user_idx"
}
],
"columns": [
{
"name": "name",
"type": "VARCHAR"
},
{
"name": "keyspace_id",
"type": "VARBINARY"
}
],
"column_list_authoritative": true
}
}
If a query goes across multiple shards and ordering is needed on the name column that is now specified as VARCHAR, then VTGate will leverage mysql to additionally the weigh_string of that column and use that value to order the merged results.
If column_list_authoritative is false or not specified, then VTGate will treat the list of columns as partial and will not automatically expand open-ended constructs like select *.
Vtgates also have the capability to track the schema changes and populate the columns list on its own. To know more about this feature, read here.
Advanced usage #
The examples/demo also shows more tricks you can perform:
- The
musictable uses a secondary lookup vindexmusic_user_idx. However, this lookup vindex is itself a sharded table. music_extrasharesmusic_user_idxwithmusic, and uses it as Primary Vindex.music_extradefines an additional Functional Vindex calledkeyspace_idwhich the demo auto-populates using the reverse mapping capability.- There is also a
name_infotable that showcases a case-insensitive Vindexunicode_loose_md5.