Reparenting
Once you have the cluster up and running, you should perform a trial failover using PlannedReparentShard to make sure it works as expected.
A typical use case for PlannedReparentShard is to use it during software updates. The command has a convenient avoid_tablet flag that allows you to specify the current vttablet you are going to perform maintenance on. If that is a primary, then it performs a failover to another eligible replica. Otherwise, it is a no-op.
You can also perform a "Planned Reparent" through the browser from the vtctld Dashboard.
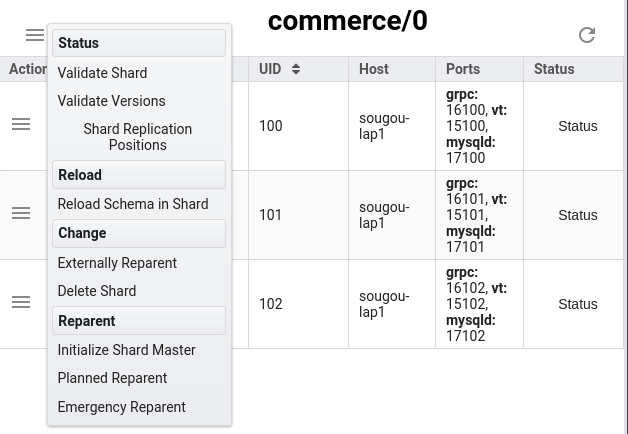
The Vitess operator performs this step automatically when a container is gracefully brought down by Kubernetes, which also takes care of the use case of a software rollout. If a container or pod is brought down abruptly or crashes, then the primary will be unavailable until Kubernetes restarts it. However, if
vtorc is also deployed, it will detect this and failover to another eligible replica as the primary. vtorc will not intervene during a graceful shut down.If you are running vtorc, you can perform the same function from the dashboard by doing a drag-and-drop operation of the nodes.
For more information, please refer to the Reparenting section.
A reparenting operation can fail in the middle. If so, it is possible for the system to be in a situation where two vttablets report themselves as primary. If this happens, the one with the newer timestamp wins. The vtgates will automatically treat the newer primary as authoritative. The system will eventually heal itself because the vttablets use a registration protocol via the global topo and the older tablet will demote itself to a replica when it notices that it is no longer the primary.
Reparenting