Update June 12, 2023: This component has been deprecated in v17 and will be removed in v18! We recommend that you instead use VTOrc with the semi_sync durability policy.
Introduction #
MySQL group replication is a new replication mechanism that was released in 2016. Group replication involves establishing a group of nodes that are coordinated automatically via Group Communication System (GCS) protocols, an implementation of Paxos. For a transaction to commit, a majority of the group has to agree on the order of a given transaction in the global sequence of transactions. Deciding to commit or abort a transaction is done by each server individually, but all servers make the same decision. In addition, group replication also provides automatic failover within a group. That is, group replication will detect failures on the node and modify the group membership accordingly by itself [0].
With the addition of group replication, there are now three popular replication mechanisms in MySQL: async-replication, semi-sync replication and (as we mentioned) group replication. However, Vitess only supports two of these out of the box with vtorc: async-replication and semi-sync replication. Although they are both battle tested, there are still issues with them: the async-replication cannot guarantee strong consistency during a failover, the new primary may not apply an update yet and it can serve stale data. for semi-sync replication, it needs sophisticated orchestration tooling to make sure the new primary has the latest update, the failover process could be error prone.
This means that two pieces of interesting technology, Vitess and MySQL group replication, do not play along with each other. This was the motivation to develop VTGR: an orchestration component that integrates Vitess and group replication.
Vitess #
Vitess adds two more components in the serving path: VTGate and VTTablet. VTGate is a proxy layer of a Vitess cluster, it knows how to route the query based on the schema and VSchema. VTTablet is the component that runs together with the mysqld process. VTTablet is the one that manages the mysqld for a shard and it talks to mysqld via local sockets. VTTablet has different types, the primary tablet needs to sit on top of a writable mysqld. Thus, write requests have to be routed to primary tablets.
A replication group constitutes a shard. Nodes within a shard share the same data through replication. The membership of the shard is stored in a topology server.
Group replication #
Group replication can be operated either in single primary mode or multi primary mode. In single primary mode, there is only one primary mysqld that is writable, all others are read only replicas.
With the single primary mode, there is a single writable node and all replicas will replicate from the primary after there is a consensus within the group. Things are easier to reason about with a single writable node and that’s what we chose to start with.
VTGR #
VTGR is a stateless orchestration component that glues Vitess with group replication. It acts a bit like a mechanic on an assembly line, checking the functioning of the system and repairing parts of it as needed. For every shard, VTGR will periodically pull Vitess topology and mysql group for diagnosis. Based on the diagnosed result, VTGR will execute corresponding repair actions.
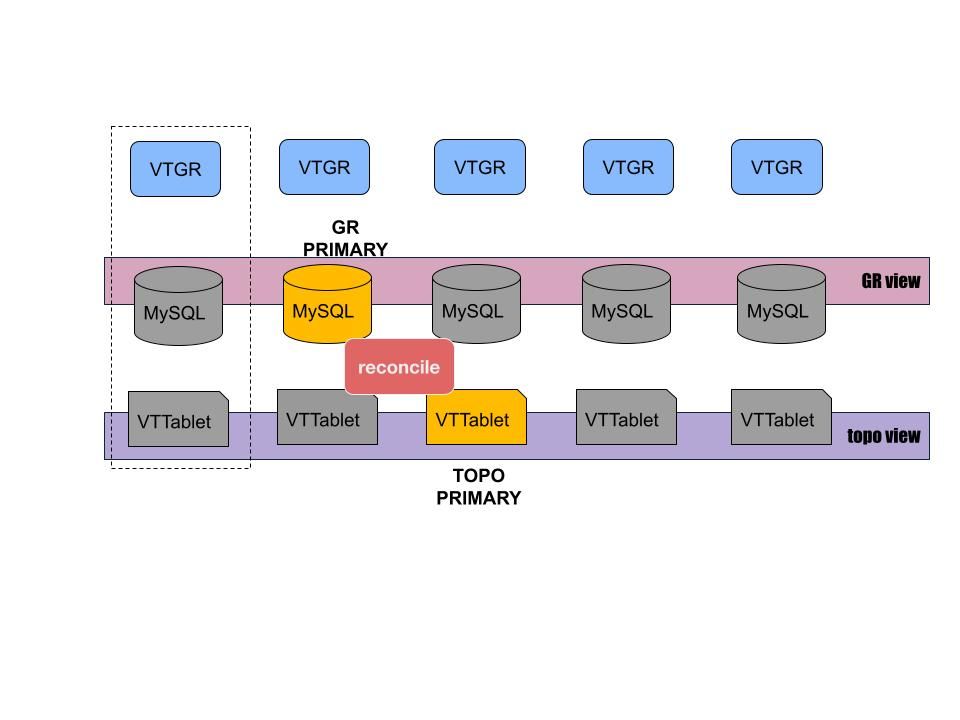
Key capabilities #
VTGR provides two key capabilities:
Group maintenance
After collecting information from the topology server and all the nodes within the shard:
If there is no active MySQL group, VTGR will bootstrap one.
If there is a replica in the shard that is not in the group, VTGR will add the replica into the group.
Automatic failover
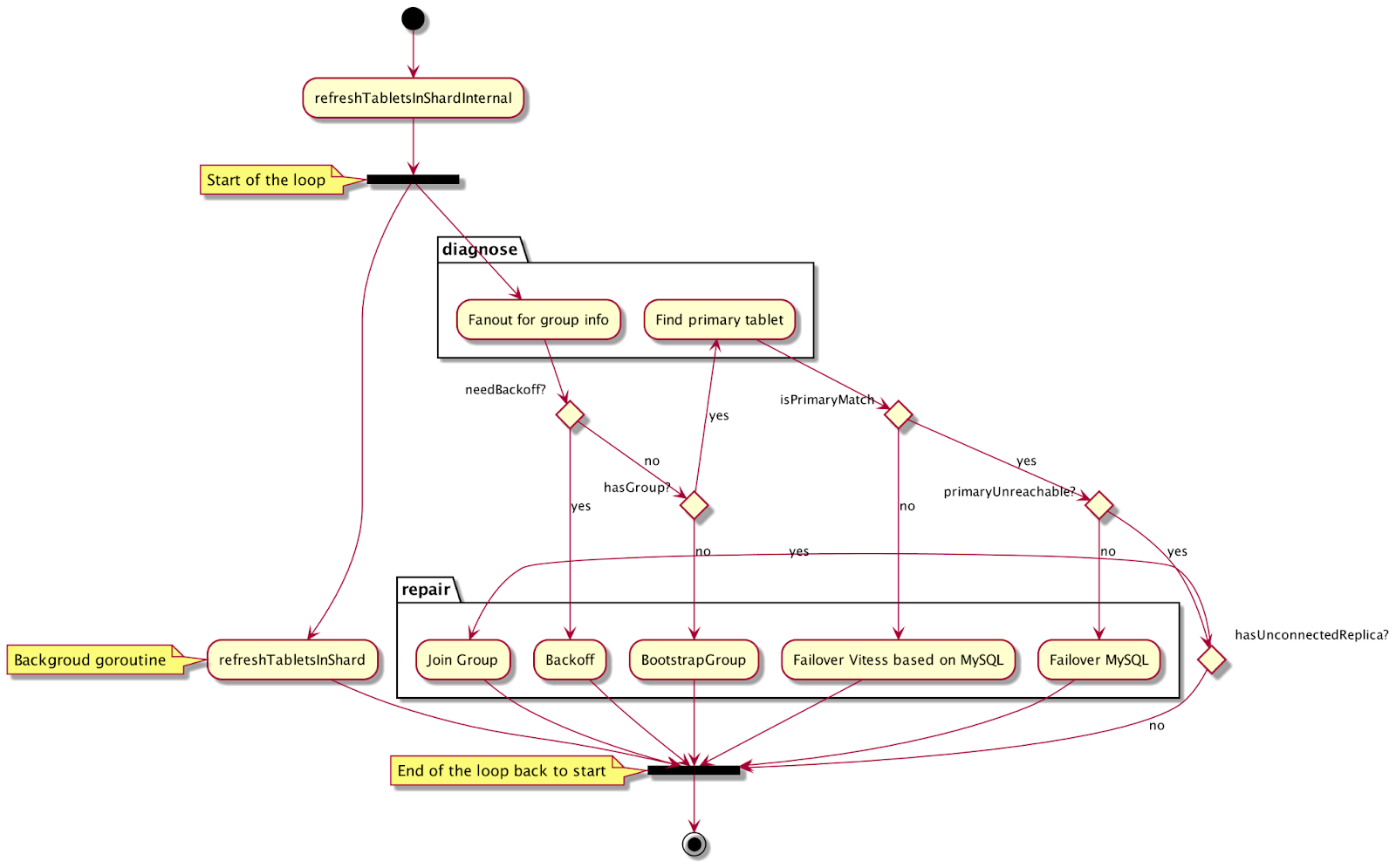
The MySQL group will failover automatically. VTGR is responsible for reconciling Vitess and the MySQL group to make sure that the primary VTTablet is pointing to a writable mysqld. To do that, VTGR uses group information to identify primary SQL node and compare it with the primary tablet from the topology server:
If there is no primary tablet, VTGR will set the primary according to the MySQL group.
If the primary tablet is not pointing to a writable primary SQL node, VTGR will change the primary according to the MySQL group.
If the primary tablet crashes but the mysqld underneath is still running, VTGR will failover the MySQL group first and then change the primary tablet accordingly.
The failover behavior above can be captured in the following activity diagram:
Performance #
Group replication is configured in single primary mode. From our experiment, VTGR only introduces a very small amount of overhead. An unplanned primary failover takes about 8 seconds to finish and the majority of the time was spent by MySQL group itself. This means within a healthy AWS region, our storage layer can recover from a node failure (e.g., disk failure, network failure, etc) in 8 seconds, this provides us with a baseline for availability and reliability for future improvements for our customers.
Future improvements #
The existing VTGR has run through multiple rounds of integration testing and chaos testing, but there is more work to be done: The current version of VTGR only supports group replication in single primary mode. It would be valuable to explore the multi-primary mode in the future, which should provide lower failover time. There are strict compatibility requirements for a MySQL group. This can be improved by fetching MySQL version in VTGR and instructing VTGR to follow those rules to support operations like version upgrade.
Summary #
It is subjective which MySQL replication mechanism fits your use case better. But VTGR bridges the gap between Vitess and group replication, making it possible to do horizontal sharding easily with group replication.
This project has benefited a lot from the entire OSS community and VTGR has now been accepted by Vitess upstream officially. We are always looking forward to getting feedback from the community.
Acknowledgements #
This work wouldn’t have been possible without continuous advice and support from various people from the community: Deepthi Sigireddi, Harish Mallipeddi, Meng Wang, Shlomi Noach, and Sugu Sougoumarane.
Reference #
[0] https://dev.mysql.com/doc/refman/8.0/en/group-replication-background.html