This post explains the inherent problem of running online schema changes in MySQL, on tables participating in a foreign key relationship. We'll lay some ground rules and facts, sketch a simplified schema, and dive into an online schema change operation.
Our discussion applies to gh-ost, pt-online-schema-change, and VReplication based migrations, or any other online schema change tool that works with a shadow/ghost table like the Facebook tools.
Why Online DDL? #
Online schema change tools come as workarounds to an old problem: schema migrations in MySQL were blocking, uninterruptible, aggressive in resources, replication unfriendly. Running a straight ALTER TABLE in production means locking your table, generating high load on the primary, causing massive replication lag on replicas once the migration moves down the replication stream.
Vitess supports managed schema changes which allows user to schedule migrations, track, cancel, retry them, possibly revert them, and more.
FOREIGN KEY Constraints overview #
In the relational model tables have relationships. A column in one table indicates a column in another table, so that a row in one table has a relationship one or more rows in another table. That's the "foreign key". A foreign key constraint is the enforcement of that relationship. A foreign key constraint is a database construct which watches over rows in different tables and ensures the relationship does not break. For example, it may prevent me from deleting a row that is in a relationship, to prevent the related row(s) from becoming orphaned.
Sample model #
Consider the following extremely simplified model. Don't judge me on the oversimplification, we just want to address the foreign keys issue here.
CREATE TABLE country (
id INT NOT NULL,
name VARCHAR(255) NOT NULL,
PRIMARY KEY (id)
);
CREATE TABLE person (
id INT NOT NULL,
country_id INT NOT NULL,
name VARCHAR(255) NOT NULL,
PRIMARY KEY(id),
KEY country_idx (country_id),
CONSTRAINT person_country_fk FOREIGN KEY (country_id) REFERENCES country(id) ON DELETE NO ACTION
);
CREATE TABLE company (
id INT NOT NULL,
country_id INT NOT NULL,
name VARCHAR(255) NOT NULL,
PRIMARY KEY(id),
KEY country_idx (country_id),
CONSTRAINT company_country_fk FOREIGN KEY (country_id) REFERENCES country(id) ON DELETE NO ACTION
);
Some analysis, rules and facts #
In the above we have 3 tables participating in two foreign key relationship.
- We will add a 4th one later
countryis a parent table in both relationshipspersonis a child table in relationship withcountrycompanyis a child table in relationship withcountry
Let's assume/agree that
countryis a small table (maybe a couple hundred rows), and that bothpersonandcompanyare large tables (just, large enough to be a problem)MySQL doesn't support foreign keys, per se. At this time, foreign keys are implemented by the storage engine, which is InnoDB in our case.
This matters, because a foreign key in InnoDB is coupled with a table. There's a space where the foreign key exists, and that space is a table. It matters because adding or dropping a foreign key is done by an
ALTER TABLEstatement.Foreign keys don't associate to tables by name but by identity. If you
RENAMEa parent table, for example, than children's foreign keys follow the table under its new name.In the above sample model we chose
NO ACTION(akaRESTRICT), but that is of little insignificance to our discussion.MySQL allows you to disable foreign key checks for your session via
SET FOREIGN_KEY_CHECKS=0You can disable foreign key checks globally viaSET GLOBAL FOREIGN_KEY_CHECKS=0, but this does not affect existing sessions, only ones created after your statement.All Online Schema Change tools:
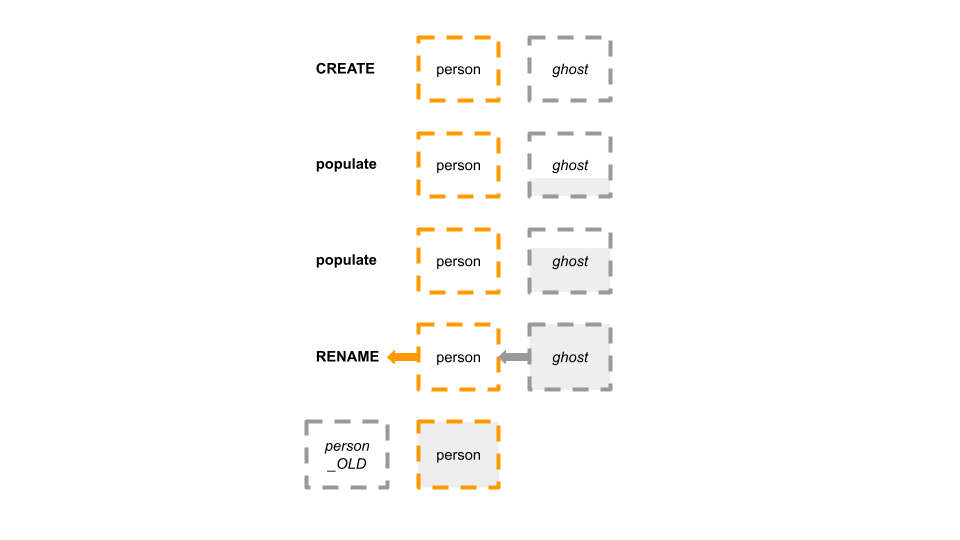
gh-ost,fb-osc,pt-online-schema-change,LHM, and Vitess'sVReplication, work by creating a "shadow" table, which I like to call the ghost table.- They create that table in the likeness of the original table.
- They modify the ghost table, and slowly populate it with data from the original table.
- At the end of the operation, in slightly different techniques, they
RENAMEthe original table away, e.g. to_mytable_old, andRENAMEthe ghost table in its place, at which time it assumes production traffic.
Changing a child table #
Say we want to ALTER TABLE person MODIFY name VARCHAR(1024) NOT NULL CHARSET utf8mb4. Or add a column. Or an index. Let's see what happens.
person has a foreign key. We therefore create the ghost table with similar foreign key, a child table that references the parent country table. Funnily, even though InnoDB's foreign keys live inside a table scope, their names are globally unique. So we create the ghost table as follows:
CREATE TABLE _person_ghost (
id INT NOT NULL,
country_id INT NOT NULL,
name VARCHAR(255) NOT NULL,
PRIMARY KEY(id),
KEY country_idx (country_id),
CONSTRAINT person_country_fk2 FOREIGN KEY (country_id) REFERENCES country(id) ON DELETE NO ACTION
);
- Notice the name of the constraint changes to
person_country_fk2. - Because
_person_ghostis a child-only table, there's no problem with it being empty. pt-online-schema-changeis based on synchronous, same-transaction, data copy via triggers. At any point in time, if we populate_person_ghostwith a row, that row also exists in the originalpersontable during that same transaction. This means the data we insert to_person_ghostis foreign key safe.gh-ost,fb-osc,Vitessuse an asynchronous approach where they tail either the binary logs or a changelog table. It is possible that as weINSERTdata to_person_ghost, that data no longer exists inperson. It is possible that there's no matching entry incountry! We can overcome that by disabling foreign key checks on our session/connection that populates the ghost table. We runSET FOREIGN_KEY_CHECKS=0and make the server (and our users!) a promise, that even while populating the table there may be inconsistencies, we'll figure it all out at time of cut-over.- Finally, population is complete. We place whatever locks we need to, ensure everything is in sync, and swap
_person_ghostin place of person.
ERROR! #
What have ended up with? Take a look:
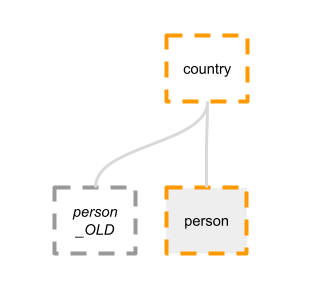
The table person_OLD still exists, and maintains a foreign key constraint on country. Now, suppose we want to delete country number 99. We delete or update all rows in person which point to country 99. Good. We proceed to DELETE FROM country WHERE id=99. We can't. That's because person_OLD still has rows where country_id=99.
Why don't we just drop that old constraint? #
To drop the foreign key constraint from person_old is to ALTER TABLE person_old DROP FOREIGN KEY person_country_fk, i.e. an ALTER TABLE. That's the very thing we wanted to avoid in the first place.
Why don't we just drop the old table? #
pt-online-schema-change offers --alter-foreign-keys-method drop_swap: to get rid of the foreign key we can drop the old table. The logic it offers is:
- Before we cut-over
- Disable foreign key checks
DROPthe original table (e.g.person)RENAMEthe ghost table in its place
Problem: DROP #
Alas, dropping a MySQL table is production is a cause for outage. Here's a lengthy discussion on the gh-ost repo. This is an ancient problem where dropping a table places locks on buffer pool and on adaptive hash index, and there's been multiple attempts to work around it. See Vitess's table lifecycle for more.
MySQL 8.0.23 release notes indicate that this bug is finally solved. Until everyone is on that version, DROP is a problem.
In my personal experience, if you can't afford to run a straight ALTER on a table, it's likely you can't afford to DROP it.
Problem: outage #
As pt-online-schema-change documentation correctly point out, we cause a brief time of outage after we DROP the person table, and before we RENAME TABLE _person_ghost TO person. This is unfortunate, but, assuming DROP is instantaneous, is indeed brief.
Child-side: summary #
Assuming MySQL 8.0.23 with instantaneous DROP, altering a table with child-side-only constraint is feasible. Without instantaneous DROP, the migration can be as blocking as a straight ALTER.
Changing a parent table #
What happens if we naively try to ALTER TABLE country ADD COLUMN currency VARCHAR(16) NOT NULL?
We create a ghost table, we populate the ghost table, we cut-over, and end up with:
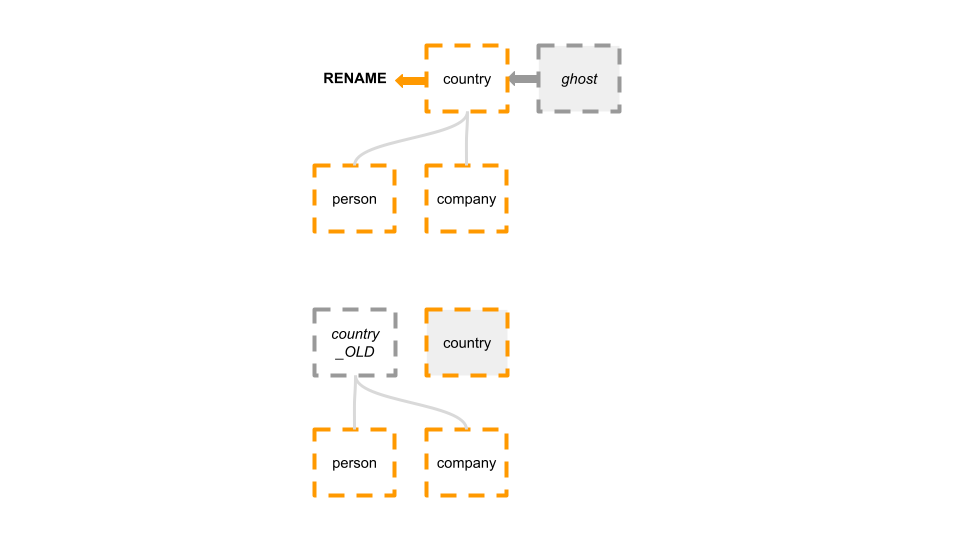
Our naive approach fails. As we RENAME TABLE country to country_OLD, the children's foreign keys, on person and company, followed the table entity into country_OLD. We are now in a situation where there is no active constraint on country, and we're left with a legacy table that affects our production.
Just drop the old table? #
Other than the DROP issue discussed above, this doesn't solve the main problem, which is that we are left with no constraint on country.
ALTER on parent implies ALTER on children #
The overwhelming result of our naive experiment, is that if we want to ALTER TABLE country, we must - concurrently somehow - also ALTER TABLE person and - concurrently somehow - ALTER TABLE company. On the children tables we need to DROP the old foreign key, and create a new foreign key that points into country_ghost.
That's a lot to unpack.
How does pt-online-schema-change solve this? #
pt-online-schema-change offers --alter-foreign-keys-method rebuild_constraints. In this method, just before we cut-over and RENAME the tables, we iterate all children, and , one by one, run a straight ALTER TABLE on each of the children to DROP the old constraint and to ADD the new constraint, pointing to country_ghost (imminently? to be renamed to country).
This must happen when the ghost table is in full sync with the original table, or else there can be violations. For pt-online-schema-change, which uses synchronous in-transaction trigger propagation, this works. For gh-ost, Vitess etc., which use the asynchronous approach, this can only take place while we place a write lock on the original table.
As pt-online-schema-change documentation correctly indicates, this makes sense only when the children are all very small tables.
Let's break this down even more.
Straight ALTER on children, best case scenario? #
Best case is achieved when indeed all children tables are very small. Still, we need to place a lock, and either sequentially or concurrently ALTER multiple such small tables.
Our experience tells that on databases that aren't trivially small, the opposite is quite common: children tables are larger than parent tables, and running a straight ALTER on children is just not feasible.
Straight ALTER on children, failures? #
Even the best case scenario poses the complexity of recovering/rolling back from error. For example, in a normal online schema change, we set timeouts for DDLs. Like the final RENAME. If something doesn't work out, we timeout the DDL, take a step back, and try cutting-over again later on. But our situation is much more complex now. While we keep a write lock, we must run multiple DDLs on the children, repointing their foreign keys from the original country table to country_ghost. What if one of those DDLs fail? We are left in a limbo state. Some of the DDLs may have succeeded. We'd need to either revert them, introducing even more DDLs (remember, we're still holding locks), or retry that failing DDL. Those are a lot of DDLs to synchronize at the same time, even when they're at all feasible.
If children tables are large? #
In our scenario, person and company are large tables. A straight ALTER TABLE is not feasible. We began this discussion assuming there's a problem with ALTER in the first place.
Also, for asynchronous online schema changes the situation is much more complex since we need to place more locks.
Can we ALTER the children with Online Schema Change? #
We illustrate what it would take to run an online schema change on each of the large children, concurrently to, and coordinated with, an online schema change on the parent. Break down follows.
When can we start OSC on children? #
We want the children to point their FK to country_ghost. So we must kick the migration on each child after the parent's migration creates the ghost table, and certainly before cut-over.
Initially, the parent's ghost table is empty, or barely populated. Isn't that a problem? Pointing to a parent table which is not even populated? Fortunately for us, we again remember we can disable foreign key checks as our OSC tool populates the child table. Yes, everything is broken at first, but we promise the server and the user that we will figure it all out at cut-over time.
So far, looks like we have a plan. We need to catch that notification that country_ghost table is created, and we kick an online migration on person and on company.
When do we cut-over each migration? #
We absolutely can't cut-over country before person and company are complete. That's why we embarked on altering the children in the first place. We must have the children's foreign keys point to country_ghost before cutting it over.
But now, we need to also consider: when is it safe to cut-over person and company? It is only safe to cut-over when referential integrity is guaranteed. We remember that throughout the parent's migration there's no such guarantee. surely not while the table gets populated. And for asynchronous-based migrations, even after that, because the ghost table always lags a bit behind the original table.
The only way to provide referential integrity guarantee for asynchronous based migrations is when we place a write lock on the parent table (country). Let's try that. We lock the table for writes, and sync up country_ghost until we're satisfied both are in complete sync. Now's logically a safe time to cut-over the children.
But notice: this is a single, unique time, where we must cut-over all children, or none.
Best case scenario for cutting-over #
In the best scenario, we place a lock on country, sync up country_ghost, hold the lock, then iterate all children, and cut-over each. All children operations are successful. We cut-over the parent.
But this best case scenario depends on getting the best case scenario on each of the children, to its own. Remember, an ALTER on a child table means we have to DROP the child's old table. Recall the impact it has in production. Now multiply by n children. The ALTER on country, and while holding a write lock, will need to sustain survive DROP on both person_OLD and company_OLD. This ie best case.
Less than best case scenario is unfortunately a disaster #
We don't have the room for problems. Suppose person cuts over, and we DROP person_OLD. But then company fails to cut-over. There's DDL timeout.
We can't roll back. person is now committed to company_ghost. We can try cutting over company again, and again, and again. But we are not allowed to fail. During these recurring attempts we must keep the lock on country. And try again company. Did it succeed? Good. We can cut-over country and finally remove the lock.
What if something really fails? (hint: it happens) #
If person made it, and company does not - if company's migration breaks/fails for whatever reason - we're left in inconsistent and impossible scenario. person is committed to company_ghost, but company is still committed to country. We have to keep that lock on country and run a new migration on company! and again, and again. Meanwhile, country is locked. Meanwhile person is also locked. You can't write to person because you can't verify that related rows exist in country, because country has a WRITE lock.
Can't stress this enough: the lock must not be released until all children tables are migrated. So, for our next challenge, what happens on a failover? We get referential integrity corruption, because locks don't work across servers.
Disk space #
Remember that an OSC works by creating a ghost table and populating it until it is in sync with the original table. This effectively means requiring extra disk space at roughly the same volume as the original table.
In a perfect world, we'd have all the disk space we ever needed. In reality we don't have that luxury. Sometimes we're not sure we have the space for even a single migration.
If we are to ALTER a parent, and as by product ALTER all of its children, at the same time, we'd need enough free disk space for all volumes of affected tables, combined.
In fact, running out of disk space is one of the common reasons for failing an online schema change operation. Consider how low the tolerance is for parent-side schema migration errors. Consider that running out of disk space isn't something that just gets solved by retrying the cut-over again, and again, ... the disk space is not there.
Execution time #
Three migrations running concurrently will not run faster than three migrations running sequentially - that's my experience backed with production experiments. Eperience is they actually end up taking longer because they're all fighting for same resources.
Altering our 200 row country table ends up taking hours and hours due to the large person and country tables. The time for a migration is roughly the sum of times for all dependent migrations!
In our particular scenario we could get away with running a straight ALTER on country.
Parent-side: summary #
The operational complexity of Online Schema Changes for parent-side foreign keys is IMO not feasible. We need to assume all child-side operations are feasible, first, and we have almost zero tolerance to things going wrong. Coordinating multiple migrations is complex, and a failover at the wrong time may cause corruption
Changing a deep nested relationship #
Truly, everything discussed thus far was a simplified situation. We introduce more complexity to our story. Let's add this table:
CREATE TABLE person_company (
id INT NOT NULL AUTO_INCREMENT,
person_id INT NOT NULL,
company_id INT NOT NULL,
start_at TIMESTAMP NOT NULL,
end_at TIMESTAMP NULL,
PRIMARY KEY(id),
KEY person_idx (person_id),
KEY company_idx (company_id),
CONSTRAINT person_company_person_fk FOREIGN KEY (person_id) REFERENCES person(id) ON DELETE NO ACTION,
CONSTRAINT person_company_company_fk FOREIGN KEY (company_id) REFERENCES company(id) ON DELETE NO ACTION
);
person_company is a child of person and of company. It's actually enough that it's a child of one of them. What's important is that now person is both a child table and a parent table. So is company. This is a pretty common scenario in schema designs.
How do you ALTER a table that is both a parent and a child? #
We introduce no new logic here, we "just" have to combine the logic for both. Given person_company exists, if we wanted to ALTER TABLE person we'd need to:
- Alter
personas a child table (impliesDROPissue and outage) - Alter
personas a parent (implies alteringperson_companyand synchronizing the cut-over)
How do we alter country now? #
To ALTER TABLE country, we'd need to:
- Begin
countryOSC, wait tillcountry_ghostis created - Then, begin
personOSC, wait tillperson_ghostis created, and - Begin
companyOSC, wait tillcompany_ghostis created - Then, begin OSC on
person_company - Run until all of the migrations seem to be ready to cut-over
- Place lock on
country. while this lock is in place:- Sync up
personmigration. Place lock onperson, and - Sync up
companymigration. Place lock oncompany. - While both locks are in place:
- Sync up
person_company DROP person_company_OLD- Cut-over
person_company
- Sync up
DROP company_OLD- Cut-over
company DROP person_OLD- Cut-over
person
- Sync up
- Cut-over
country
Throughout this complex process we have near zero tolerance to any failure in the above, and we can't afford a failover during that time.
Overall summary #
Online schema change tools are here for a long time, as MySQL does not offer sufficient support for live schema changes. But supporting FOREIGN KEYs is unfortunately not feasible given the design of online schema change tools.