Vitess introduces a new way to run schema migrations: non-blocking, asynchronous, scheduled online DDL. With online DDL Vitess simplifies the schema migration process by taking ownership of the operational overhead, and providing the user a simple, familiar interface: the standard ALTER TABLE statement.
Let’s first give some background and explain why schema migrations are such an issue in the databases world, and then dive into implementation details
The relational model and the operational overhead #
The relational model is one of the longest surviving models in the software world, introduced decades ago and widely used until today. SQL is similarly old and solid, and you may find SQL or SQL-like languages even in non-relational databases.
The relational model makes sense for many common use cases, and entities with attributes (tables and columns, respectively) map well to popular constructs like users, products, memberships, messages, etc., and SQL is expressive enough to be able to construct both simple and complex questions.
But historically, the relational model came with a price. While many database systems optimize for reads and writes, they do not optimize as much for metadata changes, and in particular for schema changes. And one of the greatest challenges with such changes is that they require an operational undertaking, and are mostly outside the developer’s domain.
In the early days, it was common for database administrators (DBAs) to act like databases’ bodyguards. They would hold off “crazy requests” from developers. Requests for changes would go through lengthy procedures and paperwork.
Thankfully these days are mostly behind us, and we work more collaboratively with continuous deployments and rapid development. Alas, the new change intensifies the problem. In the old days, you'd make a schema change once a month; maybe even once in a few months. You'd plan for this, literally ship a new version for this. Today, it's not uncommon for the busiest database deployments in the world to run multiple schema migrations per day.
Which re-introduces and intensifies the schema migration problem: the process is mostly outside the domain of the developers. It requires them to be database experts. With multiple migrations per day it requires them to collaborate and sync with other developers in ways that are not compatible with their development flow (e.g. it's completely unlike comparing and merging git branches). In small companies, you'll see developers just owning and running their migrations as they see fit, but that doesn't scale, and the larger the product and organization, the more there's a need for a more formal flow.
In the MySQL world, direct schema migrations are blocking, if not on the primary then on replicas. They’re aggressive on resources and can’t be interrupted or throttled. Online schema change tools have been around for more than a decade, but they introduce their own complexity: you’d need to install them alongside the database, allow access, schedule the execution, login, execute, inform those tools on how to throttle, handle errors, provide visibility into their actions, and more. It’s very common in companies of scale to have dedicated DBA or Ops teams who execute schema changes manually. These teams can spend hours per week or even per day by just handling the operational overhead of schema migrations.
For developers, this is a loss of ownership. While they own the idea of adding a column to some table, they need to request assistance from external teams, and often wait without much visibility into the state of progress. This breaks their flow. Perhaps one of the greatest appeals of NoSQL databases is that they don’t impose this level of constraint over a developer’s flow.
And for DBAs, schema migrations are a burden. An unexpected interruption from some developer to their own flow of work.
Some operational complexity #
The operational overhead begins with the fact that a schema migration spans multiple domains. Let’s look at an incomplete breakdown of the schema migration flow:
- Formalizing: someone (developer?) needs to formalize the migration. Typically someone will come up with a
CREATE,DROP, orALTER TABLEstatement. Is this the correct statement? Is it syntactically valid? Does it conflict with existing conventions? - Discovery: where in production does this statement need to run? The developer may not be aware of how schemas are deployed across different clusters. What’s the discovery mechanism? And, given we found the correct cluster, which server acts as the primary for that cluster? Is the data sharded? If so, how do we detect all of the shards?
- Scheduling: is there already a migration running on desired clusters? Databases react poorly to concurrent migrations; better to run them in sequence. Do we need to wait? For how long? Will someone grab our slot if we go to sleep? Will we then lose another day of work?
- Execution: do we need to log in to some server? Where are we expected to run our online schema migration tools? What command line flags should we pass?
- Monitor: can we tell what the progress is? Can we make it visible for everyone to see? How do we inform interested parties when the migration is complete?
- Cleanup: schema migration tools for MySQL leave artifacts behind: large tables that need to be dropped. Dropping tables is in itself a problem. How do we automate the cleanup for those artifacts?
- Recovery: how do we proceed if migration failed? Is there an extra cleanup to be made?
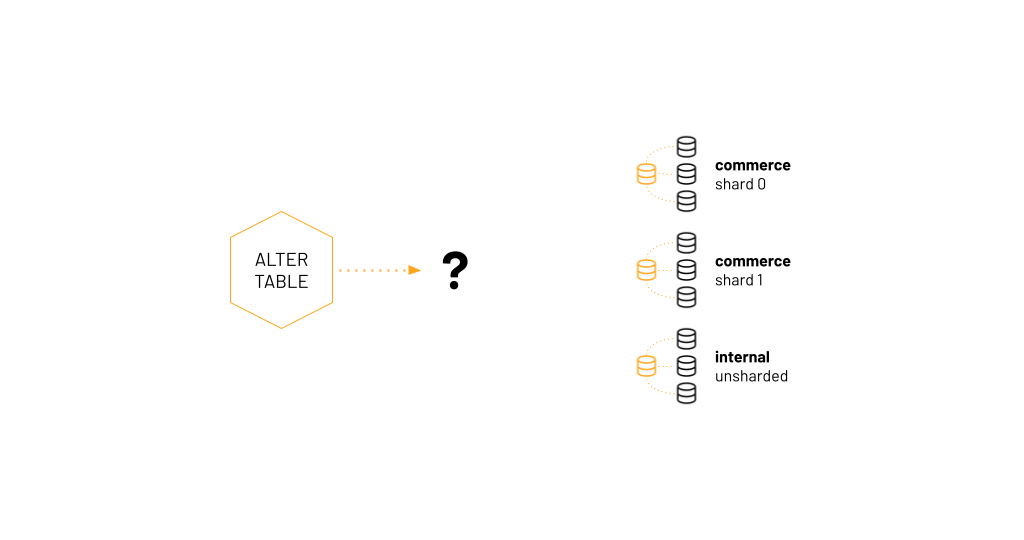
With multiple clusters in production, some of which are sharded, what is the discovery mechanism for identifying the correct clusters, and those clusters' primaries, for applying schema changes?
Where Vitess fits in #
Vitess’s architecture puts it in a unique position to address the majority of the schema migration flow. For example:
- Discovery is trivial. Vitess internally maps all schemas to shards and clusters, and knows, at any given time, where a migration (or any query, for that matter) should be applied.
- Vitess impersonates a monolithic database. Users access Vitess through vtgate, a smart proxy that understands queries, semantically. When Vitess intercepts a query, it does not strictly have to send the query to the backend database servers. With online DDL, Vitess takes note of the schema change request and schedules it for later. The appropriate backend tablets will pick up that request, and will each schedule it to avoid running concurrent migrations.
- The tablets execute online schema migration tools themselves. Today, Vitess supports
pt-online-schema-changeandgh-ost. The tablets decide how to execute those tools, provide the command line flags, any necessary hooks/plugins. Moreover, on Linux/amd64gh-ostis precompiled and bundled with Vitess, so there’s no need for installation. Vitess instructs the tools to use its own internal throttling mechanism, so the tools don’t need to worry about which replicas to monitor. The throttling mechanism dynamically adapts to topology changes. - Vitess provides an interface to query migration progress, across all shards. In addition, it provides an interface for aborting a migration, or for retrying an aborted or a failed migration.
- Vitess understands which artifacts are generated by the schema migration tools. In fact, it instructs them on what artifacts to generate. Whether successful or failed, Vitess can clean up after the migration. It will send the artifact tables to the garbage collection mechanism. It will clean up leftover triggers for a
pt-oscmigration. Vitess creates a temporary account for each migration, and destroys it once migration is complete. - Vitess knows when a migration has failed and runs the appropriate cleanup, even if Vitess itself fails along with the migration. At this time Vitess offers a one-time auto-retry for a migration failure caused by a failover.
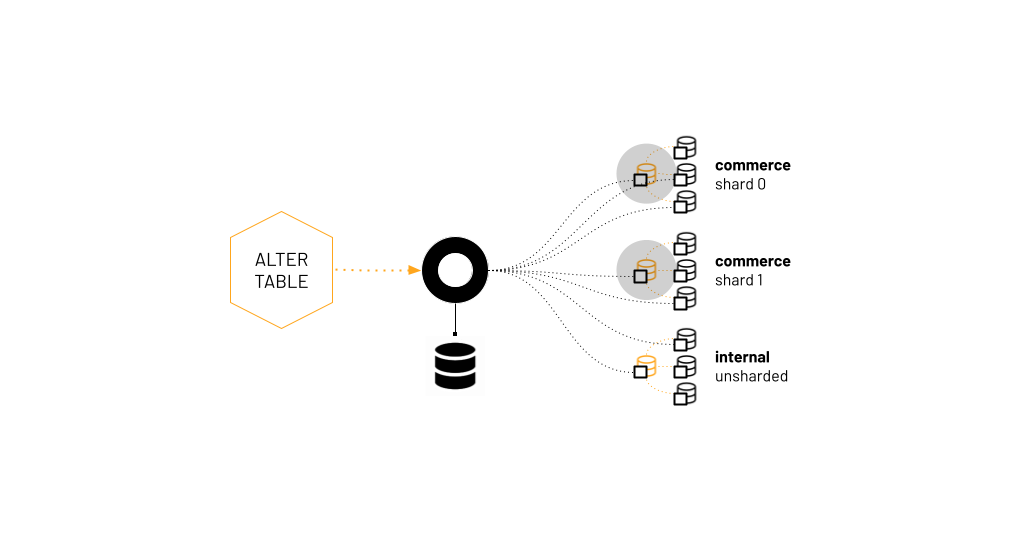
Vitess knows where schemas are deployed, what shards exist, who the primaries are at any given time, and can apply DDLs on the correct database servers without user’s intervention.
What does it look like to the user? #
The objective in developing Vitess’s online DDL was to hide all that complexity from the user as much as possible. To that effect, all the user needs to run is:
SET @@ddl_strategy=’gh-ost’;
ALTER TABLE my_table ADD COLUMN some_column INT NOT NULL;
The ALTER TABLE statement itself is completely normal, but responds differently. It returns instantly, with a job ID with which the user can track the migration’s progress. The user may choose between a gh-ost strategy, pt-osc strategy, or plain direct strategy (not an online DDL).
Where do we go from here? #
There are many ways to proceed, short term and long term. Eventually, we’d want online DDL to work seamlessly across a resharding process. Also, it could work across a planned or unplanned reparent.
Online DDL is labeled experimental as we collect user feedback.
Please see the documentation on the Vitess website
There’s more... #
Online DDL is not limited to ALTER TABLE statements. DROP TABLE statements suffer from locking issues, too. In a next blog post we will drill down into Vitess's table lifecycle, a garbage collector for unused tables.